Google Summer of Code with Kubernetes
by Nikhita Raghunath
This post originally appeared on the CNCF website. This is a technical deep dive into my Google Summer of Code project. If you want to skip the technical details and want to read about my general experience, jump to here.
My Google Summer of Code project with CNCF was to improve “ThirdPartyResources” in Kubernetes. ThirdPartyResources were succeeded by the much more stable CustomResourceDefinitions in 1.7.
CustomResourceDefinitions provide a way to extend the Kubernetes API and define your own object kinds. Once a CustomResourceDefinition (CRD) has been created, you can create objects or instances of these kinds. These custom objects are called “CustomResources”. You can read more about CRDs here.
Combined with custom controllers, this gives you a powerful way to encode domain knowledge for specific applications (operators) into an extension of the Kubernetes API.
However, there is more work needed to make CustomResources really look like native resources and this is where my project comes in.
My project tackled two important problems:
-
Validation for CustomResources - When adding objects for a custom type, create and update operations succeed as long as the contents were valid JSON. There was no way to prevent invalid objects to be stored on the server side. This is now solved by validation via JSON schema and will be present in 1.8.
-
SubResources for CustomResources - CustomResources do not have a spec/status split, that is, they are free-form JSON. This also means that we do not provide subresources for them. As a part of GSoC, a design proposal has been created to add /status and /scale subresources for CustomResources. The proposal is still in discussion and will mostly be implemented for 1.9.
Before discussing further, I’d like to mention that none of this would have been possible without the help from my mentor, Dr. Stefan Schimanski. He has been a fantastic mentor and guide!
Now, let’s see each feature in detail separately.
Validation
If you would like to read in further detail, the design proposal, implementation PR and the docs PR are available.
What this means for you
-
The biggest benefit of validation is to prevent entering any invalid data. This can help you to avoid any garbage data getting into your system. Example: If you have a replicas field, anyone can set the value to something huge like 10,000! If it is not protected, then the whole cluster could be DOSed by one malicious actor.
-
Validation will provide consistency and you can enforce a particular structure for your resource.
-
Since this uses OpenAPI schema (a variant of JSON Schema), the validation schema in a CustomResourceDefinition can be used to automatically provide documentation in the future. Moreover, you will be able to create Java and Python clients using OpenAPI as the basis.
Change in the API
A new field Validation is added to the spec of the CustomResourceDefinition (CRD). OpenAPI v3 schema is used for validation under CRD.Spec.Validation.OpenAPIV3Schema. The language is essentially JSON Schema. OpenAPI builds on that and we use that dialect to be able to reuse the specs for documentation. This way it will be possible to build clients for Java, Python and other languages in the future based on the OpenAPI spec.
OpenAPI provides a standardized declarative specification language. Different keywords are utilized to put constraints on the data. Thus it provides ways to make assertions about what a valid document must look like.
It is already used in Swagger/OpenAPI specs in Kubernetes so client side validation by adding this dynamically to the main OpenAPI spec might come in future versions.
// CustomResourceDefinitionSpec describes how a user wants their resource to appear.
type CustomResourceDefinitionSpec struct {
// Group is the group this resource belongs in
Group string
// Version is the version this resource belongs in
Version string
// Names are the names used to describe this custom resource
Names CustomResourceDefinitionNames
// Scope indicates whether this resource is cluster or namespace scoped.
// Default is namespaced
Scope ResourceScope
// Validation describes the validation methods for CustomResources
Validation *CustomResourceValidation
}
// CustomResourceValidation is a list of validation methods for CustomResources.
type CustomResourceValidation struct {
// OpenAPIV3Schema is the OpenAPI v3 schema to be validated against.
OpenAPIV3Schema *JSONSchemaProps
}How to use validation
Enable the feature gate
Please note that CustomResourceValidation is an alpha feature in an already beta API. So it is not on by default and exists behind a feature gate. To use this feature, you need to enable the feature gate. This can be achieved by passing the following flag (along with others) to kube-apiserver (Google Container Engine will also allow to create alpha clusters to play with this feature as soon as they support 1.8).
$ kube-apiserver --feature-gates CustomResourceValidation=trueCreate a CustomResourceDefinition
Now that the setup is taken care of, let’s create a CRD:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: apps.mygroup.example.com
spec:
group: mygroup.example.com
version: v1
scope: Namespaced
names:
plural: apps
singular: app
kind: App
listKind: AppList
validation:
openAPIV3Schema:
properties:
spec:
properties:
version:
type: string
enum:
- "v1.0.0"
- "v1.0.1"
replicas:
type: integer
minimum: 1
maximum: 10
storage:
properties:
memory:
type: string
pattern: "^[0-9]+(Mi|Gi)"
retention:
type: string
pattern: "^[0-9]+(h|d|m|y)"The schema in the above CRD applies following validations for the instance:
-
spec.versionmust be a string and must be either “v1.0.0” or “v1.0.1”. -
spec.replicasmust be an integer and must have a minimum value of 1 and a maximum value of 10. -
spec.storage.memorymust be a string and must be of the form described by the regular expression. Example: “500Mi”. -
spec.retentionmust be a string and must be of the form described by the regular expression. Example: “3d”.
Now that we are clear with how it is structured, it’s time to create the CustomResourceDefinition:
$ kubectl create -f crd.yaml
customresourcedefinition "apps.mygroup.example.com" createdCreate a CustomResource
With the CustomResourceDefinition created we can create instances, called CustomResources:
1. Invalid CustomResource:
This is an object of kind App which has:
- invalid
spec.version- “v1.0.2” - invalid
spec.replicas- 15
apiVersion: mygroup.example.com/v1
kind: App
metadata:
name: example-app
spec:
version: "v1.0.2"
replicas: 15
storage:
memory: "500Mi"
retention: "2d"Create it using kubectl:
$ kubectl create -f app.yamlSince it is invalid, we get an error. The last two lines show the fields where validation failed and the schema that these fields must satisfy.
The App "example-app" is invalid: []: Invalid value: map[string]interface {}{"apiVersion":"mygroup.example.com/v1", "kind":"App", "metadata":map[string]interface {}{"creationTimestamp":"2017-08-31T20:52:54Z", "uid":"5c674651-8e8e-11e7-86ad-f0761cb232d1", "selfLink":"", "clusterName":"", "name":"example-app", "namespace":"default", "deletionTimestamp":interface {}(nil), "deletionGracePeriodSeconds":(*int64)(nil)}, "spec":map[string]interface {}{"replicas":15, "retention":"2d", "storage":map[string]interface {}{"memory":"500Mi"}, "version":"v1.0.2"}}:
validation failure list:
spec.replicas in body should be less than or equal to 10
spec.version in body should be one of [v1.0.0 v1.0.1]- Valid CustomResource
This is a valid object of kind App:
apiVersion: mygroup.example.com/v1
kind: App
metadata:
name: example-app
spec:
version: "v1.0.0"
replicas: 3
storage:
memory: "500Mi"
retention: "2d"Create it using kubectl:
# create the example-app
$ kubectl create -f app.yaml
app "example-app" created
# verify that it was created successfully
$ kubectl get apps
NAME AGE
example-app 5sNote: If the schema is made stricter later, the existing CustomResources might no longer comply with the schema. This will make them unchangeable and essentially read-only. To avoid this, it is the responsibility of the user to make sure that any changes made to the schema are such that the existing CustomResources remain validated.
How it works internally
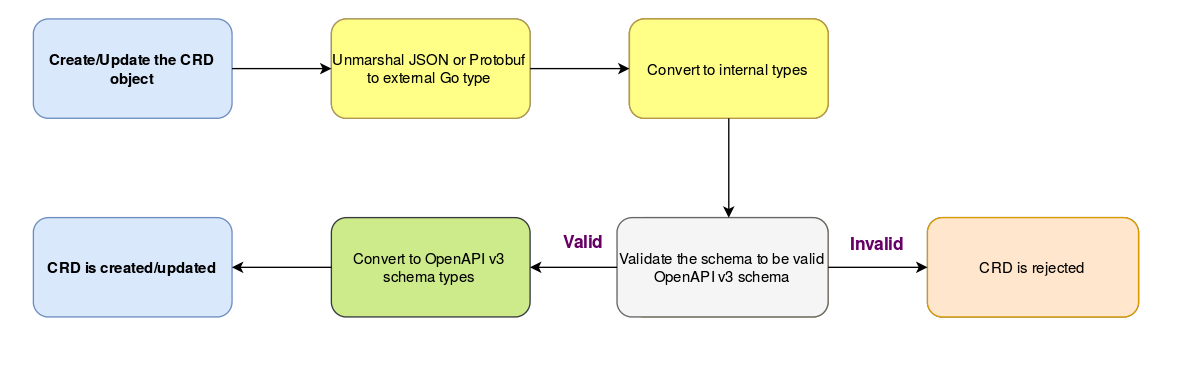
Creating a CRD
Let’s see what happens under the hood for validation when you create a CRD using $ kubectl create -f crd.yaml.
-
The Kubernetes API implementation has two major components - the internal structures and the versioned (external) APIs. The internal representation of an API object is decoupled from any version and provides a lot of freedom to evolve the code. For CRDs, the current such external version is
v1beta1. -
When you create a CRD using kubectl, the HTTP path tells the apiserver which version to use. A JSON or protobuf decoder converts this payload to the v1beta1 Go types (
types.goandtypes_jsonschema.go). -
The
v1beta1types are now converted to the internal types using (mostly) autogenerated conversion functions. In some cases, custom conversion functions (conversion.go) are also used. -
Then the schema in
.Spec.Validation.OpenAPIV3Schemais validated to ensure that it complies to OpenAPI v3 (apiextensions/validation.go). -
Once the schema is validated, the internal types are converted to go-openapi’s (go-openapi is a Go implementation of the OpenAPI standard) types (
validation.goandcustomresource_handler.go) to use an OpenAPI validator. -
Now, your CRD is created and the schema is ready to be used for validation of CustomResource instances.
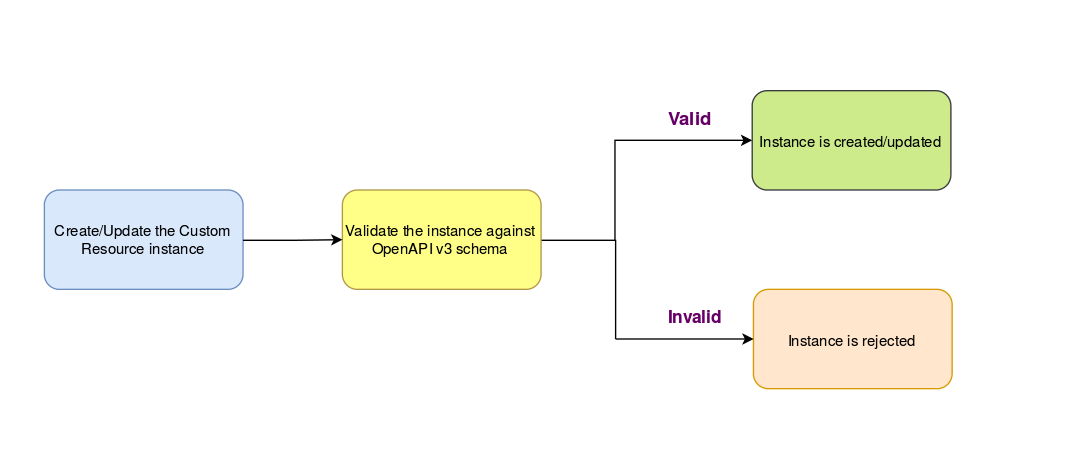
Creating a CustomResource
-
When you create such an instance of this custom type i.e. the CustomResource, the whole object is validated against the schema in the create and update handlers for the CustomResource (
strategy.go). -
If the object is invalid, it will be rejected and you can avoid entering invalid data.
This was all about validation. Let’s shift focus to Subresources now.
SubResources
As a part of Google Summer of Code, I also submitted a design proposal along with my mentor, Dr. Stefan Schimanski, to add /status and /scale subresources for CustomResources. This proposal was fun to write and taught me a lot about the existing API semantics! Moreover, it spawned a number of discussions on what the existing API semantics in Kubernetes actually are. If you are interested in contributing to Kubernetes, the design proposal might prove useful to you too.
API Semantics
Just like validation, a new field is introduced in the spec of CustomResourceDefinition - called SubResources. SubResources can be of two types - Status and Scale (in Kubernetes there are some more special purpose subresources, but for CRDs we concentrate on these two).
The custom resource instance is free-form JSON (possibly validated though with CRD validation), so we need to know the JSON paths to spec and status. These JSON paths are mentioned in the SubResources field in the CRD. Hence, we get a spec/status split for CustomResources.
Now subresources can make use of this structure. Let’s take a look at each subresource separately.
Status
Firstly, some background about how Kubernetes works: The API makes a distinction between the specification of the desired state of an object (the nested object field called “spec”) and the status of the object at the current time (the nested object field called “status”). A controller tries to bring the current state to the desired state.
In this case, a custom controller can use the status field to inform about the current status of whatever is being managed by it. The controller can write to the status endpoint, updating the .status path in the CustomResource. After this, the whole object is validated again to ensure .status does not contain incorrect values.
One main reason to have the spec/status split is that one can restrict access to the spec and the status independently. E.g. a user should only be able to modify the spec, while the controller should only be able to write the status.
Scale
There are two common ways to use the scale subresource:
- A custom controller (like an autoscaler) can write to the
/scaleendpoint. - Using kubectl scale.
In such a setup, CustomResources can be used to control other resources (like pods). These resources can now be scaled as per the the number of desired replicas mentioned in the spec.replicas JSON path.
As an example, imagine that a CustomResource describes a certain kind of pods, like a ReplicaSet does in Kubernetes itself. Let’s say the CustomResource describes the nodes of a distributed database (like Cassandra). If the amount of data or the load of a website goes up, a custom controller can scale the DB.
After the resources are scaled, a custom controller counts the number of replicas at the current state and writes to the /status endpoint updating status.replicas. This status replica field is replicated to the /scale subresource as well.
It is extremely powerful to have subresources because custom controllers can make use of this to manage resources more efficiently and with much ease.
Experience with GSoC
As I’ve said, I feel really lucky to be working with my mentor, Dr. Stefan Schimanski. He’s been an incredible support throughout the program, and has made it a GREAT experience. I’m really thankful for him for being so detailed and thorough in his answers, and for being so consistently responsive and helpful with any of my questions or concerns. He always gave me useful pointers if I was stuck and provided positive affirmations whenever I overcame a challenge. Not only this, he also helped me to integrate with the community better. I can’t imagine a better mentor!
I have been working with the API Machinery side of things and while having an awesome mentor is awesome, working with an awesome team is double awesome! A big thanks to the whole API Machinery SIG, especially Dr. Stefan Schimanski, David Eads and Anthony Yeh for the numerous code reviews and help with the design proposal.
During GSoC, I also attended GopherCon Denver where I met Konrad Djimeli, another GSoC student from CNCF. We spoke about all the exciting, overwhelming and bewildering moments that we experienced throughout the program. It was nice meeting someone going through a similar journey!

Implementing validation taught me a lot about the tooling around the Kubernetes API - generators, marshalling, fuzzers, protobuf serialization, etc. It took a good amount of learning and effort to implement validation and it felt amazing to see it finally being merged!
Wow! CustomResource validation merged in @kubernetesio. That's huge! Kudos to our awesome @gsoc student @TheNikhita https://t.co/emeA3hgRCL
— Stefan Schimanski (@the_sttts) August 30, 2017
Love seeing #gsoc interns making impact in @kubernetesio https://t.co/zSPxOZIZx7 https://t.co/rj9ooTHFOo
— Brandon Philips (@BrandonPhilips) May 25, 2017
Google Summer of Code is an exceptional opportunity for both students and mentors.
- If you are a student, don’t think twice - apply to CNCF! You will get to learn a lot and be part of an incredibly friendly and thriving community.
- If you are already a core contributor, please consider being a mentor - you get a chance to be a mentor you wish you had when you started out. You get to be a multiplier and share your knowledge with others!
All in all, I had great fun and will continue contributing even more. This is just the beginning! ![]()
Thanks to Dr. Stefan Schimanski for reviewing drafts of this post.
Subscribe via RSS
{kind=link}